사내에서 실전 카프카 개발부터 운영까지 라는 책을 선정하여 스터디를 진행하고 있습니다.
책 첫 장에서 카프카 적용 사례(kafka use case)로 트위터와 잘란도 등을 통해서 Apache 카프카를 쓰는 이점과 사용했을 때 유용한 면들을 유익하게 소개하고 있습니다.
책 내용과 개인적으로 추가적으로 정보전달하는 부분을 넣고, 해석한 부분들도 추가해서 글을 작성했습니다.
카프카를 사용하는 이점에 어떤 것들이 있는지 봐주시면 감사합니다.

Message Queue에서의 Producer, Consumer, Topic들과 같은 개념이 생소하시다면 이전 포스팅을 봐주시고 와주시면 도움이 됩니다.
https://colevelup.tistory.com/3
Message Queue란?
서론 Apache Kafka나 RabbitMQ와 같이 MessageQueue를 활용하는 방법들이 있다. MessageQueue란 무엇이고 어떤 패턴들이 존재할까? 알아보도록 하자 Message Queue Message Message란 무엇일까? 한 시스템에서 또 다른
colevelup.tistory.com
Kafka
카프카는 소셜내트워크와 구인구직, 비즈니스를 결합한 linkedin에서 겪던 고질적인 문제들, 데이터 파이프라인 확장의 어려움, 이기종 간의 호환성, 고성능 기반 실시간 데이터 처리 어려움등의 문제를 해결하기 위해 2010년 개발되었습니다.
잘란도와 트위터의 카프카 도입 사례
Zalando와 Twitter 두 기업의 카프카 사용 사례로 도입의 당위성과 장점을 알보도록 하겠습니다.
Zalando의 사례

2008년 독일에서 설립되어 신발 판매 온라인몰로 출발한 Zalando는 꾸준한 성장으로 2020년에 실사용자 3,100만 명 연간주문 수 1억 4500만 건인 회사로 성장했습니다.
국내에도 유사한 회사가 있습니다 "무신사"입니다.
Event Driven System
Zalando 회사 규모가 커지고 사업도 다각화되면서 내부적으로 데이터에 대한 온갖 요구사항 발생했습니다.
Zalando에서는 다양한 데이터 요구사항에 대한 근본적인 해결 방안필요했습니다.
해결 방안으로 채택한 Event Driven System
Data의 변화가 Stream으로 Consumer 측에 전달되는 Event Driven System으로의 전환을 결정했습니다.
Event Driven System 이란? (EDA)
이벤트란 데이터의 변경, 생성, 삭제 등 서비스에서 의미 있는 변화를 의미합니다.
이벤트 발생 시 이벤트 스트림을 통해서 이벤트가 전달되며 해당 이벤트가 필요한 서비스들이 빠르게 이벤트를 캐치해서 이를 기반으로 동작하는 것 을 간단하게 Event Driven System이라고 합니다.
Event Driven System


예를 들어 특정 user가 특정 소프트웨어를 Favorite List에 추가하는 이벤트가 발생했다고 한다면, gom이라는 유저가 kafka를 리스트에 추가했는지 안 했는지 아려면 query를 실행하여 DB에 데이터를 직접 접근하게 됩니다.
SELECT 1 FROM User_Favorite WHERE user_id = "gom" AND software_id IN ("kafka");Favorite List에 software를 추가하는 이벤트 발생 시 DB에서 outbound Event가 발생하지 않는다면
Event의 발생을 DB에 대한 정보가 바뀐 것을 통해서 알기 때문에 발생한 Event를 처리하는 개념이 아닙니다.
초기 Zalando의 해결 방법과 Event Driven System에서의 고려사항
초기 Zalando는 RestAPI로 CRUD를 활용하여 DB의 상태를 변경시키고
변경 이벤트가 필요한 곳으로 outbound 이벤트를 전달하는 구조로 시작했습니다.
하지만 이 역시 고려해야 될 상황이 많았습니다.
오차는 줄일 수 있어도 동기화 방식에서의 한계점 존재
- 다수의 클라이언트와 다양한 네트워크 환경 내에서의 지연 없는 올바른 이벤트 전달 문제
- MSA와 같이 쪼개진 수많은 service에서 Event Stream을 통해 전달받은 이벤트를 소비하는데
outbound 이벤트가 불일치하거나 일부 데이터가 누락된다면?
데이터의 신뢰성에 문제가 생기게 됩니다. - REST API 기반 통신을 한다고 하더라도 동일한 데이터를 동시에 수정할 때 각각의 데이터에 대한 순서보장과
전송 시에 순서를 보장할 수 있는가? - 데이터 사용자들의 요구사항이 각각 다 다르다면 outbound 이벤트를 전달하는 부분에서 각각의 요구사항에 맞는 구현이 필요한가?
- 빠른 전송과 대량의 배치전송에 있어서 지원이 힘듦.
결국 들어오는 inbound 데이터와 이후 처리되는 outbound 데이터 간 정합성이 Event Driven System에서는 매우 중요합니다.
대안으로써 카프카 도입
Zalando는 비동기 방식의 대표 스트리밍 플랫폼인 카프카를 선택. Zalando가 대안으로 채택한 카프카의 장점들을 살펴봅시다
빠른 데이터 수집이 가능한 높은 처리량
Http 기반으로 전달되는 이벤트일지라도 이벤트가 카프카로 처리되는 응답시간은 한 자릿수의 밀리초(ms) 단위.
순서 보장
이벤트 처리 순서가 보장되면서 엔티티 간 유효성 검사, 동시 수정 같은 복잡성이 제거됩니다.
적어도 한 번 전송 방식
분산된 여러 네트워크 환경에서 데이터 처리에 중요한 모범사례는
멱등성(동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 경우)입니다.
적어도 한 번 전송 방식
broker는 메시지 프로토콜에서 메시지를 수신받고 메시지를 저장, 변환 등의 서비스를 제공하며 consumer에게 메시지를 전달하는 프로그램 모듈입니다.
단일 local 환경에서는 broker 역할을 하는 kafka가 하나가 될 수 있고
클러스터 환경에서는 다수의 kafka 서버가 각각 broker의 역할을 할 수 있습니다.
- producer는 메시지를 broker에게 전송합니다
- broker는 메시지 A를 잘 받고 잘 받았다는 ack를 producer에게 전달합니다.
- ack를 받게 되면 producer는 다음 메시지를 전달하고 ack를 받지 못한다면 해당 매시 지를 재전송합니다.
위와 같이 메시지를 소비하는 cousumer에서 중복에 대한 처리를 하고 메시지를 재전송할지라도 메시지에 대한 유실은 없도록 하는 것이 적어도 한 번 전송 방식입니다.
자연스러운 백프레셔 핸들링
🤔 Back pressure란? 한국어로는 ”배압” 파이프를 통해 원하는 유체 흐름에 반대되는 저항 또는 힘
Event 가 emit 되는 속도 보다 Event를 처리하는 속도가 느려 Event Input이 급격하게 쌓이는 현상
ex) 특정한 시간대에 Traffic spike가 생겨서 Event Input이 쌓여 처리량보다 Event가 더 많음
pull 방식
- consumer가 broker로부터 직접 메시지를 pull 하는 방식
push 방식
- broker가 consumer에게 메시지를 직접 push 해주는 방식
push 방식은 broker가 보내주는 속도에 의존해야 한다는 한계가 존재.
카프카는 pull 방식을 채택 복잡한 피드백이나 요구사항이 사라져 간단하고 편리하게 클라이언트 구현 가능.
강력한 파티셔닝
카프카의 파티셔닝 기능을 활용하면 논리적인 topic을 여러 개로 나눌 수 있습니다.
파티션에 적절한 키를 할당하기 위한 고려사항은 존재하나 각 파티션들은 다른 파티션들과 관계없이 처리할 수 있으므로 효과적인 수평 확장이 가능해졌습니다.
비동기
비동기 방식
- producer와 consumer 간 비동기 방식
- producer가 데이터를 생산해서 broker에게 전달하면 consumer는 원하는 topic에 해당하는 메시지를 pull 해갈뿐입니다.
- Producer와 consumer가 완벽하게 분리된 비동기 방식을 사용함에 따라 병목현상 파악과 지연 문제애 대한 재빠른 대처 가능하게 되었습니다.
새로운 애플리케이션이 나중에 메시지를 읽어가는 방식도 문제가 되지 않습니다.
📢 Zalando는 내부 데이터 처리를 간소화 함은 물론 높은 처리량을 바탕으로 데이터 처리의 확장성을 높일 수 있었고 이런 데이터 기반으로 주요 문제 해결하는 목적으로 활용.
Twitter의 사례
팔로우 or 좋아요 --> 팔로워에게 메시지전달
리트윗 --> 팔로워 타임라인에 전달
문제사항 : 속보를 빠르게 노출, 관련 광고를 사용자에게 제공, 많은 실시간 사용 사례를 다뤄야 함.
카프카로 유턴한 Twitter
초기에는 Twitter도 Kafka(0.7)를 사용했습니다.
문제점
- HDD에서 I/O 이슈
- 내구성 및 리플리케이션 미구현등의 불안정성
kafka0.7 --> 자체적인 InHouse EventBus로 전환 --> Kafka 성장 --> Kafka 전환검토
전환 목적은 비용 절감과 커뮤니티 두 가지 측면.
비용
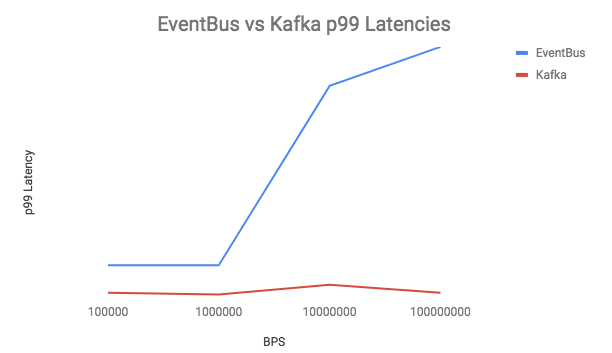
Twitter 자체적으로 Event Bus와 Kafka 성능 테스트를 감행했습니다.
BPS(Bite Per Second)와 상관없이 Latency가 거의 발생하지 않았습니다.
그 이유는????

- Event Bus는 전달하는 Serving 레이어와 Storage 레이어가 분리되어 있어서 추가적인 홉이발생.
여기서 홉은(네트워크 시간 + JVM 프록시 레이어를 통과하는 시간 모두)
반면에 카프카는 스토리지와 request Serving을 모두 처리하는 프로세스가 하나만 존재. - 파일에 변경사항에 대해서 fsync() 호출을 통해서 디스크에 기록됩니다.
Event Bus는 fsync() 호출 시 write에 대해서 명시적으로 blocking 해버리는 반면
카프카는 OS에 의존해 백그라운드로 fsync()를 처리하고 zero-copy를 사용했습니다.
zero-copy에 대해서는 아래 포스팅에서 자세히 다루므로 포스팅을 참조해주시면 감사합니다.
https://colevelup.tistory.com/23
[Kafka] Kafka와 zero-copy
이전 카프카 도입 사례에서 Twitter가 내부에서 활용하는 In-House-Event-Bus에서 kafka로 전환하계 되는 이유들 중 하나가 kafka가 zero-copy를 제공한다라는 말이 있었습니다. zero-copy에 대해서 자세하게 알
colevelup.tistory.com
결과적으로 EventBus는 Kafka 보다 동일한 워크로드를 처리하기 위해 더 많은 시스템이 필요함. 단일 소비자 사용 사례 경우 리소스 68% 절약 여러 소비자 사례의 경우 리소스가 75% 절약됩니다.
커뮤니티
커뮤니티 측면에서의 이점이 무엇이 있을까요?
- Event Bus에 필요로 하는 기능들(HDFS 파이프 라인, 정확한 한 번 전송 etc…)은 이미 카프카에 구현이 되어있다.
- 당시 트위터 Event Bus 담당 엔지니어 8명 , 자체 트러블 슈팅 가이드 제작, 인수인계사항 등 발생합니다.
Kafka - 전 세계에 수백 명 커뮤니티가 존재합니다. - 클라이언트나 broker에 문제가 발생할 시 웹에서 정보 수집 용이합니다.
- Kafka 사용 후 엔지니어 고용하기가 쉽습니다.
추가적으로 보는 Netflix와 Uber의 use case
Data Pipe Line - Neflix
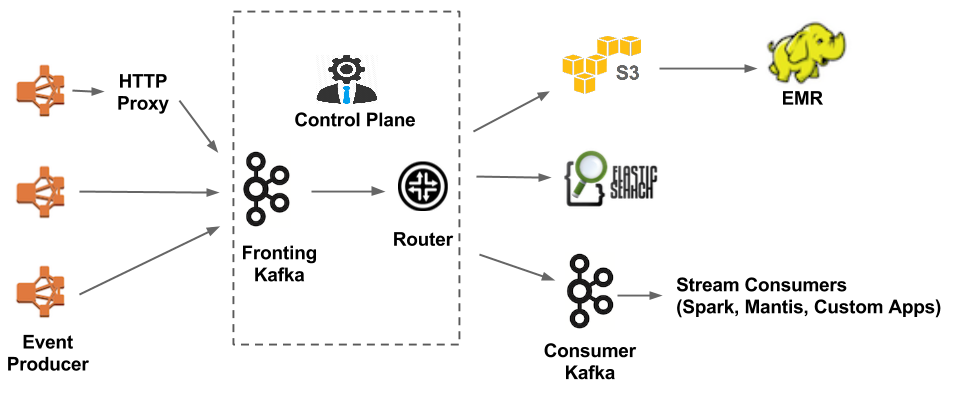
데이터 수집 / 통계 / 처리 / 적재하기 위한 파이프라인을 연결하는 역할로 카프카를 사용합니다.
비디오 시청 활동 / 사용 빈도 / 에러로그등 모든 이벤트는 데이터 파이프라인을 통해 흐릅니다.
- 데이터 버퍼링 - Kafka는 복제된 영구 메시지 대기열 역할을 함 - absorb Temporary outage
- 데이터 라우팅 - s3, Elastic, 보조 kafka 데이터 이동하는 역할을 합니다.
Data Integration - Uber
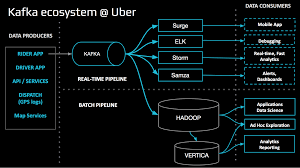
모든 데이터가 RealTime Kafka Pipe Line을 통해서 전달합니다.
- 운전자 / 탑승자 앱으로부터 Event Data 수집
- 카프카를 통해 다양한 DownStream Consumer들에게 전달.
Batch Pipe Line
- 특정 시간에 대량으로 데이터 전송합니다.
- Data 분석 활용합니다.
국내외 카프카 이용 현황
국내
Line : 내부 50여 개 서비스 카프카 이용 중, 하루에 2500억 건 넘는 메시지 처리 210TB 데이터가 카프카로 유입
- 2019년도 기준
LINE에서 Kafka를 사용하는 방법 - 1편
Kakao : 총 7개의 클러스터를 보유, 하루 2,600억 개의 메시지 처리 하루에 240TB 데이터를 카프카로 유입
- 2018년 기준
카프카 산전수전 노하우
해외
New York Times
- 카프카, 카프카 스트림즈 API를 활용 실시간으로 콘텐츠 배포
Publishing with Apache Kafka at The New York Times | Confluent
- adidas, DATADOG, Paypal, Neflix, Audi, Uber 다사용 중
카프카가 해결 방안이 되는 주된 고민 사항들
국내외 이용 현황을 보면결국 Zalando와 Twitter , LinkedIn에서 일어난 문제들은
대다수의 기업들이 공통적으로 겪는 문제점이며 카프카가 해결하기 위한 방책이 되었다는 것을 알 수 있습니다.
아래와 같은 고민을 하고 있다면 카프카는 해결을 위한 훌륭한 방안이 되어 줄 수 있습니다.
- 동기/ 비동기 데이터 전송에 대한 고민이 존재하는가?
- 실시간 데이터 처리에 대한 고민이 있는가?
- 현재 데이터 처리량에 대한 한계를 느끼는가?
- 새로운 데이터 파이프라인이 복잡하다고 느끼는가?
- 데이터 처리의 비용 절감을 고려 중인가?
카프카는 데이터 플랫폼 또는 이벤트 스트리밍 플랫폼이라고 불리며 분야를 막론하고
모든 데이터 처리 프로세싱의 핵심이자 없어선 안될 필수 요소로 자리 잡았습니다.
참조
Twitter's Kafka adoption story
'MessageSystem > Apache Kafka' 카테고리의 다른 글
| [Kafka] Kafka와 zero-copy (0) | 2023.01.30 |
|---|---|
| [Kafka] Leader Epoch(리더 에포크)을 활용한 카프카 브로커(kafka broker) 복구 (1) | 2023.01.28 |
| [Kafka] Replication(리플리케이션)과 Leader(리더)와 Follower(팔로워)를 알아보자 (0) | 2023.01.25 |
| [Kafka] Topic, Partition, Segment, Segment 관리, Offset (0) | 2023.01.21 |
| [Kafka] kafka cluster 실습 환경 구축 (0) | 2023.01.21 |




댓글