이전 카프카 도입 사례에서 Twitter가 내부에서 활용하는 In-House-Event-Bus에서 kafka로 전환하계 되는 이유들 중 하나가 kafka가 zero-copy를 제공한다라는 말이 있었습니다.
zero-copy에 대해서 자세하게 알아보도록 하겠습니다.
https://colevelup.tistory.com/16
[Kafka] Kafka 도입 사례로 보는 Kafka 사용의 당위성과 이점
사내에서 실전 카프카 개발부터 운영까지 라는 책을 선정하여 스터디를 진행하고 있습니다. 책 첫 장에서 카프카 적용 사례(kafka use case)로 트위터와 잘란도 등을 통해서 Apache 카프카를 쓰는 이
colevelup.tistory.com

Twitter의 In-House-Event-Bus
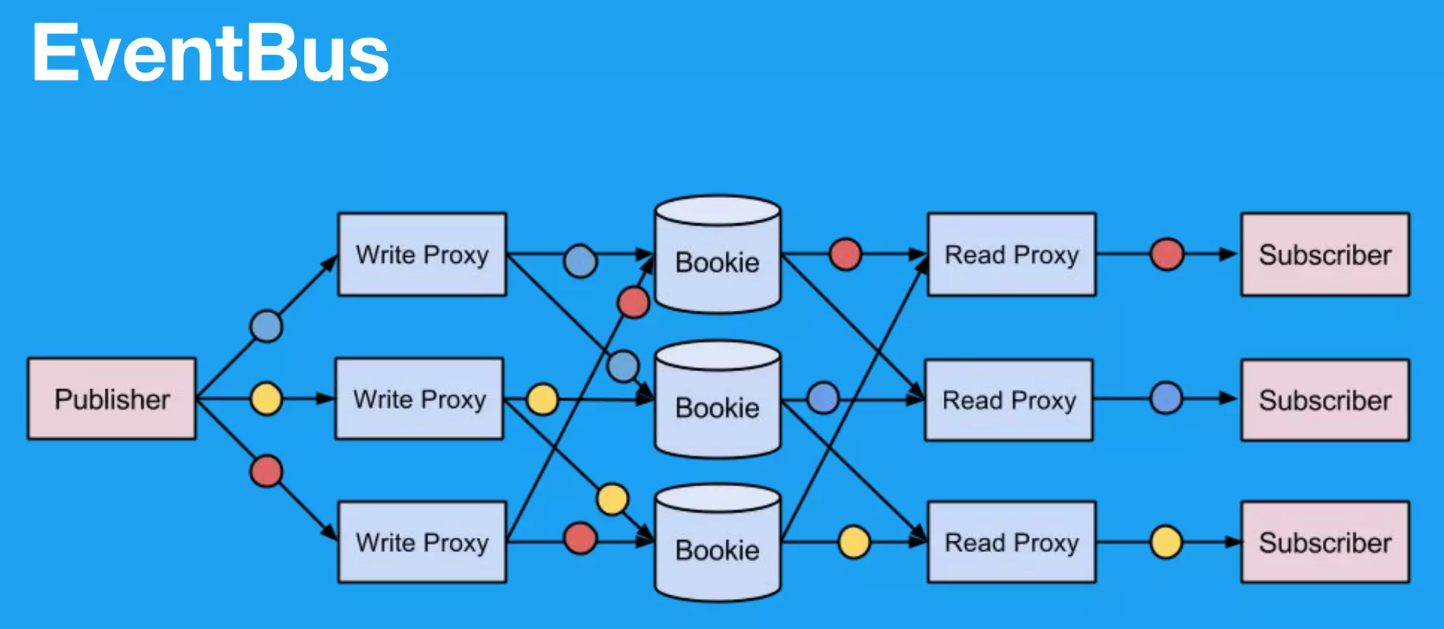
이전 Twtitter의 In-House-Event-Bus는 위 그림과 같이 pub/sub 구조의 event bus 형태를 띠고 있었습니다.
write와 read를 proxy layer로 분리한 뒤 Apache Bookeeeper를 storage layer로 활용합니다.
Bookie는 개별적인 Bookeeper server 입니다.
Apache Bookeeper에서는 storage layer로 Apache Pulsar를 활용하고 있었습니다.
https://www.confluent.io/kafka-vs-pulsar/
Kafka vs Pulsar - Performance, Features, and Architecture Compared
Pulsar vs Kafka comparison: which is best? Differences in performance, latency, scalability, and more across popular messaging/streaming platforms.
www.confluent.io
confluent에 따르면
Kafka는 분산 커밋 로그를 스토리지 계층으로 사용하며 쓰기는 로그 끝에 추가됩니다.
읽기는 오프셋부터 순차적으로 수행되며 데이터는 disk Buffer에서 network Buffer로 zero-copy 됩니다.
반대로 RabbitMQ와 Pulsar는 둘 다 인덱스 기반 스토리지 시스템을 사용합니다.
zero-copy는 별도의 복사본을 만들지 않고 한 위치에서 다른 위치로 데이터를 이동하는 데이터 전송 하는 방식으로 메모리를 절약하고 성능을 향상할 수 있는데
인덱스 기반 스토리지 시스템에서 데이터는 일반적으로 인덱스에 액세스 하여 데이터의 물리적 위치를 찾은 다음 저장 매체에서 메모리로 데이터를 복사하여 읽습니다.
RabbitMQ와 Pulsar는 개별 메시지를 승인하는 데 필요한 빠른 액세스를 제공하기 위해 데이터를 트리 구조에 보관합니다.
트리 구조가 제공하는 빠른 개별 읽기는 쓰기 오버헤드의 비용으로 발생하며, 이는 로그에 비해 쓰기 처리량 감소, 쓰기 지연 시간 증가 또는 쓰기 증폭 증가로 나타날 수 있습니다.
그렇다면 인덱스 기반 스토리지는 오버헤드 비용을 감수하고 어떤 장점을 취할 수 있을까요?
위에서 한번 언급했듯이 개별 메시지를 승인하는 데 필요한 빠른 액세스를 제공할 수 있습니다.
위와 같은 이유로 twitter의 기존 in-house-event-bus에서 kafka로 전환될 때의 이점 중 하나가 zero-copy가 될 수 있게 되었습니다.
기존 접근 방법(Traditional approach)
zero-copy가 아닌 기존방식은 어떨까요?
byte[] applicationBuffer = new byte[1024];
read(fileFd, applicationBuffer, len);
send(socketFd, applicationBuffer, len);
일반적으로 파일에서 데이터를 읽어 네트워크로 전송하는 서버코드입니다.
Buffer를 할당받고 디스크에서 파일을 버퍼로 읽어 들여서 다시 소켓으로 전송하는 형태입니다.
while을 활용 수 있지만 기본적으로 read() 시스템 콜과 send() 시스템 콜이 반복되는 형태입니다.


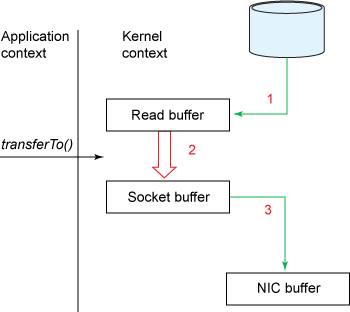
1. read() call Disk 존재하는 File Data Read buffer로 이동합니다.
2. Kernel 주소 공간에 위치한 Read Buffer는 사용자 접근 불가능 하기 때문에 Application buffer에 Read Buffer 내용을 복사, 복사 완료 시 함수 호출에서 리턴합니다.
3. send() 함수 호출 Application buffer를 파라미터로 전달, Kernel 영역에 위치한 Socket buffer로 데이터를 복사합니다.
4. Socket Buffer에 있는 데이터는 실제 네트워크로 전송하기 위해 NIC 에 있는 buffer로 다시 복사합니다.
5. Read Buffer, Application Buffer, Socket Buffer, NIC Buffer 4가지 Buffer에 동일한 데이터가 복사되는 과정은 cpu자원을 소모합니다.
보통 이런 Buffering은 메모리와 디스크 메모리와 네트워크 장비사이 속도차이를 만회하려고 만들어진 성능 개선 장치입니다.
ex) 1KB 작은 데이터를 파일에서 읽으면 커널은 1KB 이후 커널이 유지하는 버퍼 사이즈만큼 데이터까지 한 번에 읽어서
페이지 캐시에 로드 후 이후 요청 시 I/O를 수행하지 않고 캐시에서 읽어서 사용자에게 전달.
데이터를 미리 읽어서 성능 개선하는 방식입니다.
하지만 이런 Buffering이 성능 저하를 유발하는 병목으로 작용할 수 있습니다.
ex) 사용자가 요청하는 데이터 크기가 커널이 유지하는 버퍼 사이즈보다 큰 경우
미리 읽어서 캐싱하는 성능 개선 < 여러 단계에 걸쳐 데이터 복사하는 비용
제로카피(Zero Copy)
linux 2.2 sendfile() 시스템콜
#include <sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t * offset ", size_t" " count" );
Java nio 패키지 transferTo(), transferFrom() 메서드로 구현입니다.
public void transferTo(long position, long count, WritableByteChannel target);
Kafka는 Java의 NIO 패키지에 transferTo()를 사용합니다.
fileDesc.transferTo(offset, len, socket);
transferTo() 한 번의 콜로 가능해졌습니다.
1. transferTo() 메서드를 이요 파일 전송 요청 read()와 send()가 하나로 합쳐진 형태의 시스템콜입니다.
2. read() 시스템 콜과 마찬가지로 DMA 엔진이 디스크에서 파일 읽어서 Read Buffer로 복사합니다.
3. 커널 모드에서 바로 Socket Buffer로 데이터 복사합니다.
4. Socket Buffer에 복사된 데이터를 NIC buffer로 복사합니다.
5. 데이터 전송 transferTo() 메서드에서 리턴합니다.
Application Buffer로 데이터들이 복사되지 않기 때문에 복사본이 4군데에서 3군데로 줄어듭니다.
4개에서 3개 중 하나만 CPU와 관련되어 있게 됩니다.
더욱 개선된 zero-copy
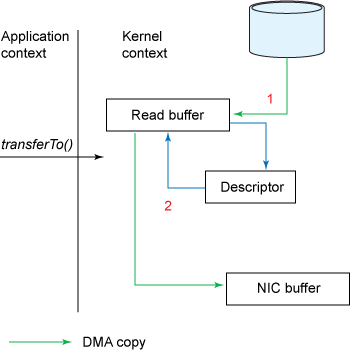
리눅스 커널 2.4 이후 버전에서는 NIC 장비가 "Gather Operation"을 지원할 경우 복사본을 더 줄일 수 있게 되었습니다.
1. 사용자가 transferTo() 메서드를 호출합니다.
DMA 엔진이 디스크에서 파일을 읽어 커널에 위치한 Read buffer로 데이터를 복사합니다.
2. 데이터가 소켓 버퍼로 복사되지는 않습니다.
대신 데이터가 저장된 위치와 데이터 사이즈에 대한 정보와 함께 디스크립터(descriptor)가 소켓 버퍼에 추가됩니다.
DMA 엔진은 이 정보를 이용해 Read buffer에 있는 데이터를 NIC 버퍼에 바로 복사하고, 네트워크로 데이터를 전송합니다.
성능 비교표 (by IBM)
| File size | Normal file transfer (ms) | transferTo (ms) |
| 7MB | 156 | 45 |
| 21MB | 337 | 128 |
| 63MB | 843 | 387 |
| 98MB | 1320 | 617 |
| 200MB | 2124 | 1150 |
| 350MB | 3631 | 1762 |
| 700MB | 13498 | 4422 |
| 1GB | 18399 | 8537 |
참조
https://www.confluent.io/kafka-vs-pulsar/
https://stackoverflow.com/questions/9770125/zero-copy-with-and-without-scatter-gather-operations
https://docs.oracle.com/cd/E19455-01/806-1017/sockets-48/index.html
'MessageSystem > Apache Kafka' 카테고리의 다른 글
| [Kafka] 카프카(kafka) 프로듀서(Producer)의 파티셔너 (Partitionor), 배치(Batch) 그리고 메시지 전송 방식 (0) | 2023.02.04 |
|---|---|
| [Kafka] Leader Epoch(리더 에포크)을 활용한 카프카 브로커(kafka broker) 복구 (1) | 2023.01.28 |
| [Kafka] Replication(리플리케이션)과 Leader(리더)와 Follower(팔로워)를 알아보자 (0) | 2023.01.25 |
| [Kafka] Topic, Partition, Segment, Segment 관리, Offset (0) | 2023.01.21 |
| [Kafka] kafka cluster 실습 환경 구축 (0) | 2023.01.21 |




댓글