카프카(kafka)가 리더 에포크(Leader Epoch)를 활용하여 카프카 브로커(kafka broker)를 복구 하는 과정에 대한 정리와, 실습 환경 내에서 브로커 복구 진행 과정을 살펴보는 것을 포스팅해보도록 하겠습니다.
실전 카프카 개발부터 운영까지 도서에 정보를 추가하고 자체적인 실습환경 내에서 진행 했습니다.

실습 환경에대해서는 아래 환경 구축을 참조해 주시면 감사합니다.
https://colevelup.tistory.com/17
[Kafka] kafka cluster 실습 환경 구축
서론 kafka 관련 포스팅을 하기 이전 실습 환경에 대해서 먼저 구성해 보도록 하겠습니다. container 환경에서 실습환경은 진행됩니다. 가상화 기술과 Docker, 대량의 Container를 효율적으로 띄우고 관
colevelup.tistory.com
Replication에 대한 개념과 Leader Follower에 대한 정보를 얻고자 하신다면 이전 Replication 포스팅을 확인해 주시면 감사합니다.
https://colevelup.tistory.com/19
[Kafka] Replication(리플리케이션)과 Leader(리더)와 Follower(팔로워)를 알아보자
리플리케이션(Replication) 데이터 파이프라인에 메인 허브 역할을 하는 카프카 클러스터가 정상적으로 동작하지 못한다거나 연결된 데이터 파이프라인에 영향을 미친다면 심각한 문제가 생길 수
colevelup.tistory.com
리더 에포크 (Leader Epoch) 란?
Ledaer-Epoch는 Partition의 Replicas들이 서로서로 일치하도록 하는 replication 프로토콜에서 사용되는 개념입니다.
Leader-Epoch는 컨트롤러에 의해 관리되는 32bit 숫자로 표현되며, 이 값은 Partition의 현재 상태를 판단하는데 사용됩니다.
이 값들은 replication 프로토콜에 의해 전파됩니다.
kafka cluster 내에서 각 Partition 마다 Leader-Epoch-Checkpoint라는 파일에 고유의 정수 값이 있습니다.
Leader-Epoch는 복구동작시 High-Water-Mark를 대체하는 수단으로 활용되는데 왜 Leader-Epoch가 복구동작시 필요한지 이번 포스팅에서 확인해보도록 하겠습니다.
Leader-Epoch를 활용하지 않은 상태에서의 Kafka 브로커 복구
Leader-Epoch를 사용하지 않은 상태에서 특정 시점에서
Follower가 Error가 발생해서 Down 되고 추후 복구가 된다면?
예시를 통해 확인하겠습니다.
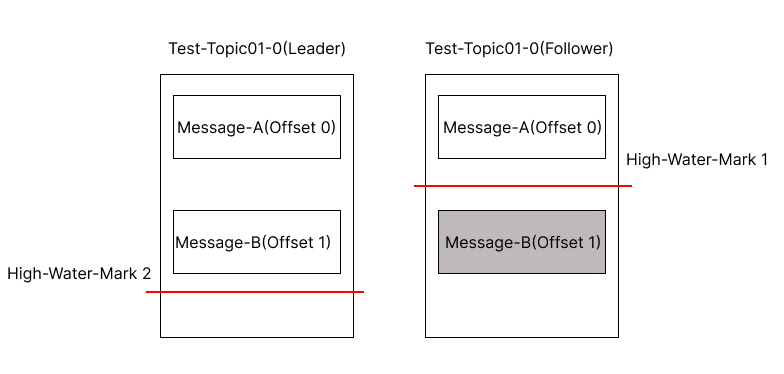
1. Leader는 Message-B를 Producer로부터 받은 뒤 1번 Offset에 저장합니다.
2. Follower는 Message-B에 대해 Leader에게 가져오기 요청을 보내고 Leader의 응답으로부터 High-Water-Mark의 변화를 감지하고 High-Water-Mark를 1로 올립니다.
3. Follower는 1번 Offset의 message-B 메시지를 Replication 합니다.
4. Follower는 2번 Offset 대한 요청을 보내고 Leader는 High-Water-Mark를 2로 올립니다.
5. Follower가 Message-B를 Replication 하긴 했지만 High-Water-Mark를 올리라는 Leader의 응답을 받지 않은 이 시점에 Follower가 다운돼버립니다.
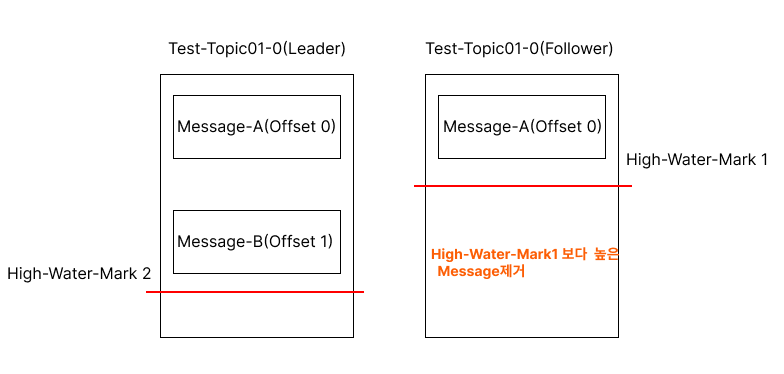
Follower가 장애에서 복구가 되면 kafka는 내부적으로 메시지 복구 동작을 진행합니다.
1. Follower는 자기가 갖고 있는 메시지 중에 자신의 High-Water-Mark보다 높은 메시지는 신뢰할 수 없다고 판단하며 삭제합니다.
2. Follower는 Offset 1의 새로운 메시지에 대해 가져오기 요청을 보냅니다
3. 하지만 이 순간에 Leader가 다운돼버립니다.

Leader Error 발생 이후 Follower가 기존 Leader의 Offset 1에 있던 Message-B가 없이 승격되었기 때문에 새로운 Leader는 Message-B를 갖고 있지 않게 됩니다.
즉 Leader가 변경되는 과정을 통해서 Message가 손실될 수 있습니다.
Leader-Epoch를 활용해서 다시 kafka 브로커를 복구해봅시다.
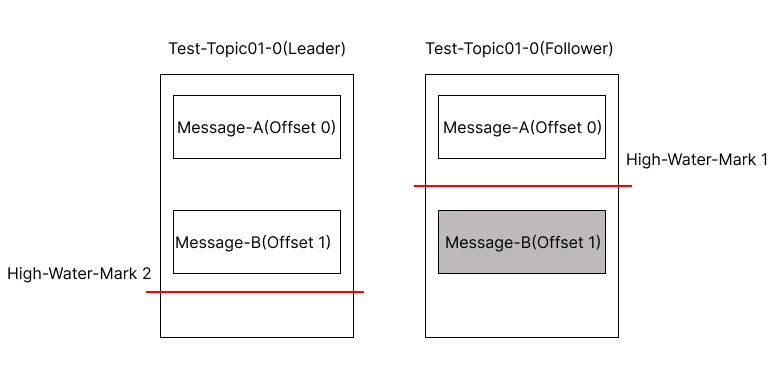
Follower가 장애에서 복구된 이후 상황이라고 가정해 봅시다.
기존의 경우 High-Water-Mark 보다 앞에 있는 메시지들은 신뢰할 수 없는 메시지로 판단하여 전부 삭제한다고 했습니다.
Leader-Epoch를 사용하는 경우에는
1. Follower가 메시지 복구동작을 하면서 Leader-Epoch 요청을 보냅니다.
2. Leader는 Leader-Epoch에 대한 응답으로 Offset1의 Message-B 까지라고 Follower에게 보냅니다.
3. Follower는 High-Water-Mark 보다 높은 Offset 1의 Message-B를 삭제하지 않고 High-Water-Mark를 상향조절 합니다.

Leader가 Down이 되고 Follower가 새로운 Leader로 승격되어도 이전 Follower의 복구과정에서 Leader-Epoch를 통해 High-Water-Mark를 올리고 Message를 보존했기 때문에 Message 손실이 발생하지 않습니다.
Leader와 Follower가 동시에 다운되는 경우에는?
Leader만 Offset1에 Message-B를 저장했고 Follower는 Offset1 Message-B를 아직 Replication을 완료하지 못한 상태에서 Leader와 Follower둘다 장애가 발생해서 Down 됐다고 가정하고 Leader-Epoch를 사용하지 않고 복구를 해보겠습니다.
Follower였던 브로커가 먼저 복구가 됩니다.

1. Follower가 먼저 복구가 되었고 Partition에 Leader가 존재하지 않기 때문에 새로운 Leader로 승격됩니다
2. 새로운 Leader는 Producer로부터 Message-C를 받고 Offset1에 저장한 뒤 High-Water-Mark를 상향 조정합니다.
추후 기존 Leader였던 브로커가 복구가 됩니다.

1. 기존에 Leader 였던 브로커는 Topic에 0번 Partition에 이미 Leader가 있으므로 복구된 브로커는 Follower가 됩니다.
2. Follower는 Leader와 High-Water-Mark를 비교를 하고 비교를 해보니 일치하므로 브로커는 메시지를 삭제하지 않습니다.
3. Leader는 Message-D를 받고 Offset 2에 위치시키고 Follower는 Replication을 할 준비를 합니다.
Leader와 Follower가 동일한 High-Water-Mark를 나타내고 있지만 서로의 메시지가 다르게 됩니다.
Leader-Epoch를 활용해서 다시 복구해 봅시다.
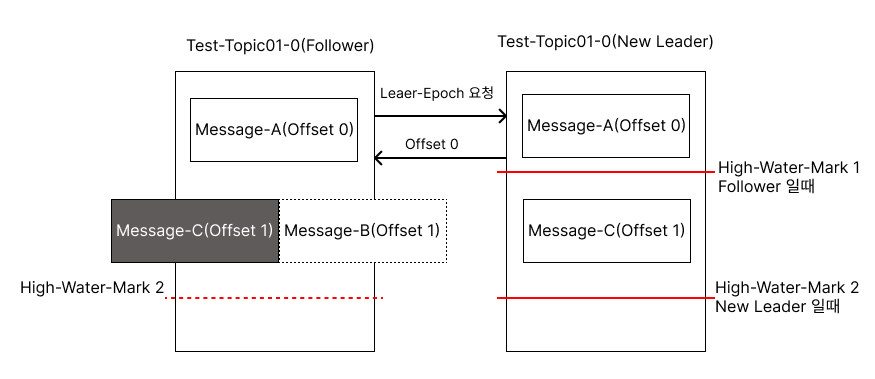
1. 기존 Leader였던 브로커가 장애에서 복구되고 이미 Leader가 있기 때문에 Follower가 됩니다.
2. Follower는 Leader에게 Leader-Epoch 요청을 보내고 Leader는 Offset 0까지 유효하다고 응답합니다.
3. Follower는 유효하지 않은 Offset 1번에 있는 Message-B를 삭제합니다.
4. Follower는 Offset 1번에 있는 Message-C를 Replication 할 준비를 합니다.
이와 같은 과정을 통해서 메시지가 달라지는 것을 막을 수 있습니다.
Leader-Epoch 실습하기
🤔 그럼 도대체 Leader는 어떻게 Offset 0번까지 유효한지 알 수 있었을까요?
Leader-Epoch 요청과 응답에는 Leader-Epoch 번호와 Commit 된 Offset 번호를 활용합니다.
이 부분은 실습으로 진행하면서 자세히 살펴보도록 하겠습니다.
토픽생성부터 하겠습니다.
/opt/kafka/bin $ kafka-topics.sh --bootstrap-server kafka1:9092 --create --topic LEP-test01 --partitions 1 --replication-factor 2
토픽 상세 보기 명령어를 실행하여 Topic의 Partition Leader가 어느 브로커인지 확인합니다.
/opt/kafka/bin $ kafka-topics.sh --bootstrap-server kafka1:9092 --topic LEP-test01 --describe

Partition Leader 브로커와 Follower 브로커는 다를 수 있으므로 직접 확인하시길 바랍니다.
저의 경우 Leader 브로커는 2번이고 Follower는 1번으로 되어 있습니다.
이제 Leader 브로커로가서 Leader-Epoch 상태를 확인해 보도록 하겠습니다.
${docker-compose.yml있는 경로}/$ docker-compose exec kafka2 bash
kafka/kafka-logs-${hash}/LEP-test01/cat leader-epoch-checkpoint
2번 브로커에 bash로 붙은 뒤 LEP-test01 토픽에 0번 파티션의 leader-epoch-checkpoint를 확인해 보도록 하겠습니다.
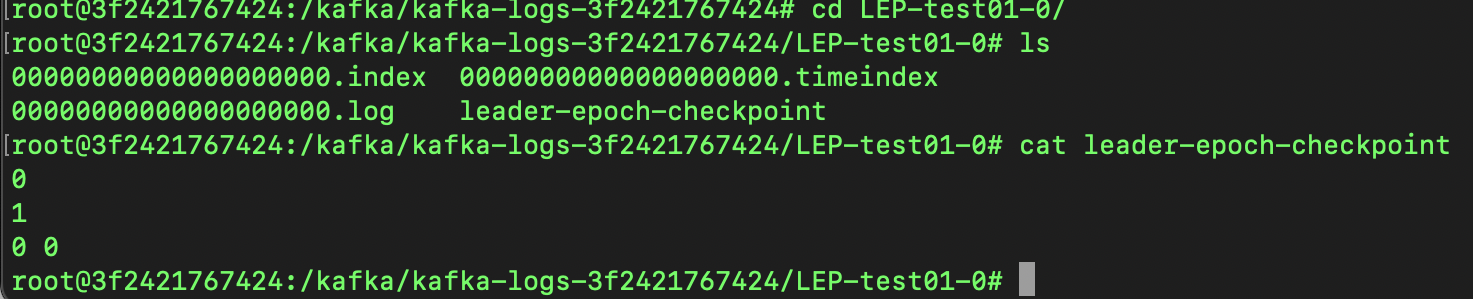
0
1
#현재의 leader-epoch 번호
0 0
#첫번째 0은 리더에포크 번호, 두 번쨰 0은 최종 커밋 후 새로운 메시지를 전송받게 될 offset 번호
메시지를 추가해서 Partition값에 변화를 주겠습니다.

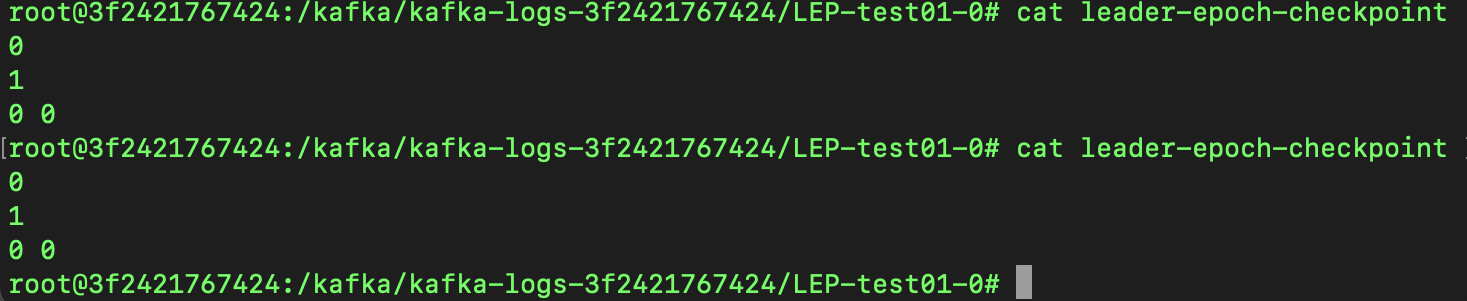
Leader-Epoch 상태는 이전과 달라진 것이 없습니다.
console producer로 전달한 Leader Epoch Test Messages는 0번 Partition에 0번 Offset에 저장되었고 Replication 동작으로 Follower까지 저장된 상태입니다.
Leader-Epoch는 새로운 Leader 선출이 발생하면 변경된 정보가 업데이트됩니다.
리더 선출을 위한 브로커 종료 실습
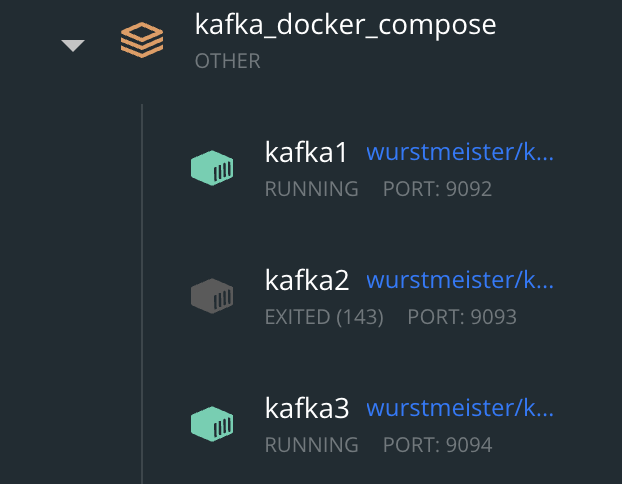
Leader가 브로커 2번이므로 kafka2 컨테이너를 강제로 종료시켜 2번 브로커가 문제가 생겨 다운된 상태를 재현해두었습니다.

Topic 정보를 확인해 보면 Follower였던 1번 브로커가 Leader로 승격한 것을 확인할 수 있습니다.
1번 브로커로가서 leader-epoch 상태를 확인해보도록 하겠습니다.

1. 현재 브로커 2번이 다운됬기 때문에 브로커 1번이 새로운 리더로 승격되었고 Leader-Epoch 번호는 Leader가 변경될 때마다 하나씩 숫자가 증가하기 때문에 2 번째 줄의 값이 1→ 2로 변경되었습니다.
2. 세 번째 줄의 첫 번째 0은 leader-epoch 번호이고 두 번째 0은 최종 커밋 후 새로운 메시지를 전송받게 될 offset 번호입니다.
3. 마지막줄의 첫 번째 1은 leader-epoch 번호이고 두 번째 1은 최종 커밋 후 새로운 메시지를 전송받게 될 offset 번호입니다.
마지막에 추가된 1 1 값에 대해서 좀 더 자세히 설명하자면.
현재는 가장 마지막에 커밋된 Offset 번호는 “Ledaer Epoch Test Message”이 메시지에 대한 Offset 값 0입니다.
leader-epoch 번호가 1인 상태에서 해당 메시지 이후에 전송받도록 준비된 Offset 번호는 1이 됩니다.
1 1로 구성됩니다.
브로커 복구 시에 leader-epoch-checkpoint 파일에 기록된 정보를 이용해 복구 동작을 하게 됩니다.
참조
'MessageSystem > Apache Kafka' 카테고리의 다른 글
| [Kafka] 카프카(kafka) 프로듀서(Producer)의 파티셔너 (Partitionor), 배치(Batch) 그리고 메시지 전송 방식 (0) | 2023.02.04 |
|---|---|
| [Kafka] Kafka와 zero-copy (0) | 2023.01.30 |
| [Kafka] Replication(리플리케이션)과 Leader(리더)와 Follower(팔로워)를 알아보자 (0) | 2023.01.25 |
| [Kafka] Topic, Partition, Segment, Segment 관리, Offset (0) | 2023.01.21 |
| [Kafka] kafka cluster 실습 환경 구축 (0) | 2023.01.21 |




댓글