엘라스틱 서치(Elastic Search)가 무엇인지, 엘라스틱 클러스터(Elastic Cluster)에서 제공하는 엘라스틱 노드(Elastic Node)들의 종류, 엘라스틱 서치 레플리카(ElasticSearch Replica), 세그먼트(Segment), 그리고 node 간 발생할 수 있는 SplitBranProblem에 대해서까지 확인해 보도록 하겠습니다.

엘라스틱 서치(Elastic Search)?
Elastic Search는 기본적으로 데이터 저장소 입니다.
엘라스틱 서치(Elastic Search) 특징
NoSQL JSON 기반 저장소.
Cluster 구성. Schemaless 구조이다.
Rest API 기반 쉬운 인터페이스를 제공
Cluster
ElasticSearch도 Cluster와 Node 환경을 제공합니다.
Cluster는 하나이상의 Node(Server)가 모인 것이며, 전체 데이터를 저장하고 모든 Node를 포괄하는 통합 Indexing 및 검색 기능을 제공합니다.
Cluster 명은 고유한 이름으로 식별되고 Default는 “elasticsearch”입니다.
Cluster 명이 중요한데 동일한 Cluster 명을 서로 다른 환경에서 재사용하면 위험합니다.
노드가 잘못된 Cluster에 포함될 위험이 존재합니다.
Cluster에 하나의 노드만 있는 것은 유효하며 문제가 되지 않습니다.
각자 고유한 클러스터 이름을 가진 독립적인 클러스터를 여러 개로 두 거나 여러 대의 서버가 하나의 클러스터를 구성하고 한 서버에 여러 개의 클러스터가 존재 가능합니다.
Node 간 데이터 교환을 위해 http port(9200-9299), tcp포트(9300-9399)를 열어둡니다.

Node와 Node 종류들에 대해서 알아보자
컴퓨터 데이터 통신망에서, 데이터를 전송하는 통로에 접속되는 하나 이상의 기능 단위. 통신망의 분기점이나 단말기의 접속점을 이름.
클러스터에 포함된 단일 서버 데이터를 저장, 클러스터의 Indexing 및 검색 기능에 참여
노드 역시 이름으로 식별되며 Default는 Node에 지정되는 UUID입니다.
네트워크의 어떤 서버가 Elastic Search 클러스터의 어떤 노드에 해당하는지 식별하기 위해 관리목적으로 이름이 중요합니다.
Cluster 이름을 통해 Node는 일부로 구성될 수 있습니다.
Default로 각 Node 들은 “elasticsearch”라는 이름의 Cluster에 포함되도록 설정됩니다.
ex) 네트워크 내에서 다수의 Node가 존재 → Node들을 실행(각각 검색 기능이 가능) → 모두가 자동으로 “elasticsearch”라는 단일 Cluter를 형성하고 Cluster의 일부가 됩니다.
네트워크에서 실행되고 있지 않은 상태에서 단일 노드를 시작한다면 Default값인 “elasticsearch”라는 단일 Node Cluster가 생성됩니다.
Master-eligible Node
master로 선출될 수 있는 node.
마스터 노드는 index를 생성, 삭제, shard 할당등 전체적으로 index나 node들을 관리하는 역할을 하는 Node입니다.
Node Cluster 구성 없이 1개 node로 elasticsearch를 사용할 경우 해당 node가 master 역할과 data를 저장하는 역할을 모두 수행합니다.
여러 node로 cluster를 구성할 경우 master 역할만 하는 node와 data를 저장하기만 하는 node로 구분해서 사용하는 것이 일반적, 즉 master는 데이터가 저장되지 않고 index 관리와 node 및 cluster 관리만 집중하게 됩니다.
Data Node
데이터를 저장하는 역할. CRUD, Search, coordinate node가 없는 경우 aggregation 쿼리도 수행합니다.
Ingest Node
preprocessing 과정을 수행하는 노드.
logstash 나 beats 혹은 RestAPI 등을 통해 데이터 저장 하기 전에 전처리를 통해 데이터를 pipe라인을 통해 변형해 저장 가능.
전처리 과정만 전문적으로 수행하는 node가 ingestnode입니다.
전처리 하는 Data가 많은 경우 ingest node가 성능향상에 도움이 될 수 있습니다.
Machine learing Node
preprocessing 과정을 수행하는 노드.
logstash 나 beats 혹은 RestAPI 등을 통해 데이터 저장 하기 전에 전처리를 통해 데이터를 pipe라인을 통해 변형해 저장 가능.
전처리 과정만 전문적으로 수행하는 node가 ingetnode 전처리 하는 Data가 많은 경우 ingest node가 성능향상에 도움이 될 수 있습니다.
Coordinating Node
사용자의 요청에 대한 일종에 로드 밸런서 역할을 하는 node 만약에 coordinating nodes가 없다면 data node가 coordinating nodes 역할을 합니다.
data node가 aggregation을 수행할 시 상당한 자원을 소모하게 됩니다.
data node의 main role인 데이터 저장보다 aggregation에 더 많은 자원을 소모하게 되어 제기능을 수행 못 할 수도 있습니다.
연관 있는 data node사이에 tasks들을 찾고 배분하는 것을 수행함. aggregation 쿼리를 받아 각 data node에 적절하게 요청을 분산하고 취합해 aggregation을 수행합니다.
노드는 각각 하나의 노드마다 하나의 역할만 하는 것이 아니라 동시에 다양한 역할을 할 수 도 있습니다.
Elastic Search 아키텍처 / 용어
RDBMS와 비교해 보는 ElasticSearch의 용어.
+---------------------------------------+-----------------------+
| RDBMS | ElasticSearch |
+---------------------------------------+-----------------------+
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Query DSL |
| SELECT * FROM | GET API |
| UPDATE <TABLE> SET | POST API |
| INSERT INTO <TABLE> | PUT API |
| Indexing on demand | Everything is indexed |
| SELECT <FIELD>, COUNT(*) FROM <TABLE> | Aggregation |
+---------------------------------------+-----------------------+
출처: https://gist.github.com/agrawalo/c7c56b6109702cd93b24405a769c2fc4#file-elasticsearchvsrdbms-txt
Index
RDBMS에서 Database와 대응하는 개념
비슷한 특성을 가진 Document(Row)들의 모음
ex) 고객데이터 Indx, 제품 카탈로그 Index, 주문데이터 Indx 각각 둘 수 있습니다.
Index 이름은 모두 소문자 여야하고 이름으로 식별됩니다.
Index 이름은 Inedx에 포함된 Doucument에 대한 Indexing, select, update, delete 작업에 해당 Index를 가리키는 데 사용됩니다.
단일 Cluster에서 원하는 Index 개수를 정의할 수 있습니다.
Indexing
데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환하여 저장하는 과정입니다.
Type
Type은 Index에서 하나 이상의 유형을 정의할 수 있습니다.
Table과 유사한 개념입니다.
의미 체계는 전적으로 사용자가 결정합니다.
Elastic Search6.x 이후로는 index당 단일 타입만 허용합니다.
ex) BlogPlatform Index
userData Type
blogData Type
commentData Type
Index당 단일 타입만 허용한 이유
🤔 왜 Elastic Search 6.x 이후로 index당 단일 타입만 허용했을까?
그 이유 중 하나는 Index에 존재하는 서로다은 Type에서 동일한 이름의 JSON 문서 필드를 만들 수 있기 때문에 의도치 않은 검색 결과가 나타나는 문제가 발생했기 때문입니다.
test_index
test_type1, test_type2 만들고 각각 하나씩 indexing 했다면.
# curl -H ’Content-Type: application/json'
-XPOST "http://localhost:9200/test_index/test_typel?pretty" -d '
{
"name": "elasticsearch",
"type_name": "test_typel"
}
,
{
"_index" : "test,index",
"_type" : "test_typel",
"_id" : "AWpzMGuKKs3l0pC—hyf",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
# curl -H 'Content-Type: application/json'
—XPOST ,,http://localhost:9200/test_index/test_type2?prettyH -d '
{
“name”: "elasticsearch",
"type_name": "test_type2"
}
,
{
"_index" : "test_index",
"_type" : "test_type2",
"_id" : "AWpzMKEZKs3l0pC-hyg",
"_version" : 1,
”result" : "created",
"_shards" : {
"total" : 2,
“successful" : 1,
"failed" : 0
},
"created" : true
}test_index에 서로 다른 타입 type1, type2에 name이라는 같은 필드가 존재합니다.
test_index에 검색 요청을 하게 될 경우 양쪽 모두 name이라는 필드가 존재하기 대문에 의도하지 않은 타입에서 문서가 검색될 가능성이 있습니다.
따라서 6.x버전부터는 하나의 인덱스에 하나의 타입만 지원하게 됐습니다.
Document
Document는 Index화 할 수 있는 기본 정보 단위.
Row와 유사함.
JSON 형식.
Sharding(shard)
sharding과 Replication 은 분산 데이터 시스템에도 존재하는 개념.
index는 방대한 양의 데이터를 저장할 수 있는데 만약 단일 노드의 하드웨어 한도를 초과하는 경우라면?
단일 노드에서 검색 요청 처리 시 속도가 느려 터질 가능성이 있습니다.
Elastic Search는 이 문제를 해결하기 위해 index를 shard라는 조각으로 분할하는 기능을 제공합니다.
index 생성 시 원하는 shard 수를 정의할 수 있음.
각각의 shard는 온전한 기능을 가진 독립적인 index이며 클러스터의 어떤 노드에서도 호스팅 가능합니다.

Elastic Search의 default shard 값은 5.
하나의 Index를 생성하고 데이터를 indexing 하게 되면 node 내부에 논리적으로 5개의 shard 생성합니다.
클러스터에 노드를 추가할 경우 shard들이 각 노드로 분산됩니다.
ex) node가 2개인 경우 shard는 3개, 2개
shard방식 및 검색 요청으로 집계되는 방식에 대한 메커니즘은 모두 ElasticSearch에서 관리합니다.
🔥 shard 수는 index 생성 후에는 변경이 불가능합니다,
index가 생성된 다음 언제라도 탄력적으로 replica의 수를 변경할 수 있습니다.
장점
- 볼륨의 수평 분할/ 확장이 가능
- 여러 shard에 분산 배치/ 병렬화 함으로써 성능/처리량을 늘릴 수 있음
Segement
Shard는 Index에 Indexing 되는 Document들이 저장되는 논리적 공간입니다.
Segment는 Shard의 Data들을 가지고 있는 물리적인 파일을 의미합니다.
Segment는 immutable의 특성을 갖게 됩니다.

Index외부엔 node가 node외부엔 Cluster가 있습니다.
Shard마다 segment 개수는 다를 수 있습니다.
Segement Immutable
update와 delete시 일반적으로 알고 있는 데이터를 수정하지 않습니다.
Segement가 불변하다는 것 → 기존 데이터를 수정하지 않는다는 것.
Segement에서 해당 데이터를 Disconnected 하고 mark 함(불용처리).
- Update 처리 시 새로 쓰고, 기존에 것을 불용 처리 합니다.
- Delete 역시 삭제 시에 바로 지우지 않고 불용 처리만 합니다.
- 추후에 해당 데이터를 지움 바로 지우지 않습니다.
이점
Lucene의 segment가 immutable 한 이유
Lucene의 segment가 immutable한 이유
Elasticsearch의 Document의 수정, 삭제 동작이 발생되었을 때 실제 Document를 구성하고 있는 각 shard 내부 Segment는 바로 지워지지 않는다. 대신 해당 세그먼트가 지워졌다고 mark만 하고 수정되었을 경우
wedul.site
단점
- 불변 특성을 유지하기 위해 작은 크기의 세그먼트가 점점 늘어나고 검색시마다 많은 수의 세그먼트들이 응답해야 한다는 단점이 발생합니다.
- Elastic Search는 백그라운드에서 세그먼트 병합으로 해당 단점을 보완합니다.
Replication(replica)
네트워크/클라우드 환경 내에서 어떠한 이유에서 오류가 발생하고 shard/Node가 오프라인 상태가 되거나 또는 사라지게 된다면?
Failover 메커니즘이 필요합니다,
ElasticSearch에서는 index shard에 대해 하나 이상의 복사본을 생성할 수 있습니다.
Replica shard라고 부름 줄여서 Replica라고 부릅니다.

각 index는 여러 개의 shard로 분할할 수 있으며 하나의 index는 replica가 없을 수도 있고 복제하여 1개 이상 replica가 존재할 수 도 있습니다.
🔥 기본적으로 Elasticsearch의 각 index는 기본 shard5개 replica 1개를 갖습니다.
replica 1이라는 말은 index를 생성하고 데이터를 indexing 하게 될 때 1개의 replica가 추가로 생성된다는 의미입니다,
ex) Cluster에 최소한 2개의 Node가 있다면? Index는 기본 shard 5개 replica shard 5개(replica 1개)를 가지므로 index당 총 10개의 shard가 존재합니다.
장점
shard/node의 오류가 발생하더라도 고가용성을 제공합니다.
📢 replica shard는 원본 shard와 동일한 node에 배정되지 않습니다.
모든 replica에서 병렬로 검색 실행할 수 있으므로 검색의 볼륨과 처리량을 확장 가능합니다.
즉 읽기 분산처리 시 활용될 수 있습니다.
Split Brain Problem
Elasticsearch 뿐만 아니라 Cluster로 작동하는 모든 서비스들은 Master Node 후보 노드를 홀수개로, 최소한 살아있어야 하는 노드 수를 n/2+1로 설정하라고 권장합니다.
예시
두 개의 노드가 있는 elasticsearch cluster에서 Node1은 Cluster 시작 시 Master로 선택되었으며 OP라는 기본 shard를 보유, Node2는 OR이라는 Replica를 보유
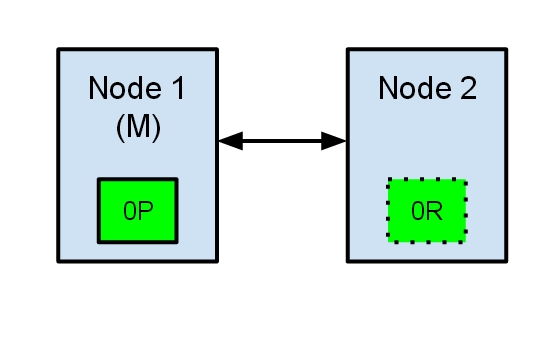
어떤 이유로 두 노드 간 통신이 실패하게 된다면?
Node 중 하나가 응답하지 않기 때문에도 발생 가능( ex: GC stop-the-world)

여기서 문제는 Node1, Node2 둘 다 모두 다른 노드가 실패했다고 생각하게 돼버립니다.
Node1은 이미 Master이므로 아무것도 하지 않으나 Node2는 Master가 Cluster 내에 없다고 생각하기 때문에 Master-eligible Node인 Node2를 Master로 선택합니다.
OR인 Replica를 더 이상 Replica로 두지 않기 때문에 OR을 OP로 승격시킵니다.

각자의 클러스터에 데이터가 추가되거나 변경되고 나면 나중에 합쳐졌을 때 데이터 정합성 문제가 생기고 데이터 무결성이 깨지게 됨.
How to avoid the split-brain problem
elastic search 6.x 이하버전
elasticsearch.yml 파일에서 discovery.zen.minimum_master_nodes 설정 값을 변경하는 것 N/2 + 1로 해당 값을 설정해야 하며 N은 클러스터의 마스터 후보 노드의 수. 마스터 후보 노드의 수는 홀수로 지정해야 합니다.
🤔 discovery.zen.minimum_master_nodes Master를 선택하기 위해 통신해야 하는 노드의 수를 말함 default는 1
위 예시→ (2/2+1) = 2 → 2
두 노드 간 네트워크가 끊어지면 Node1은 Master 상태를 잃고 Node2도 Master로 선출되지 않습니다.
홀수로 지정한 나머지 한 개의 마스터 후보 노드가 살아있다면 마스터 노드로 승격
elastic search 7.x 이상
cluster.initial_master_nodes → master 노드 후보 리스트
cluster.initial_master_nodes : 과반수 이상이 살아있어야 Cluster 동작
즉 클러스터가 스스로 minimun_master_nodes 노드 값을 변경하도록 변경.
참조
기본 개념 | Elasticsearch 설명서 [5.4] | Elastic
https://github.com/exo-archives/exo-es-search
How to avoid the split-brain problem in elasticsearch - Trifork Blog
댓글